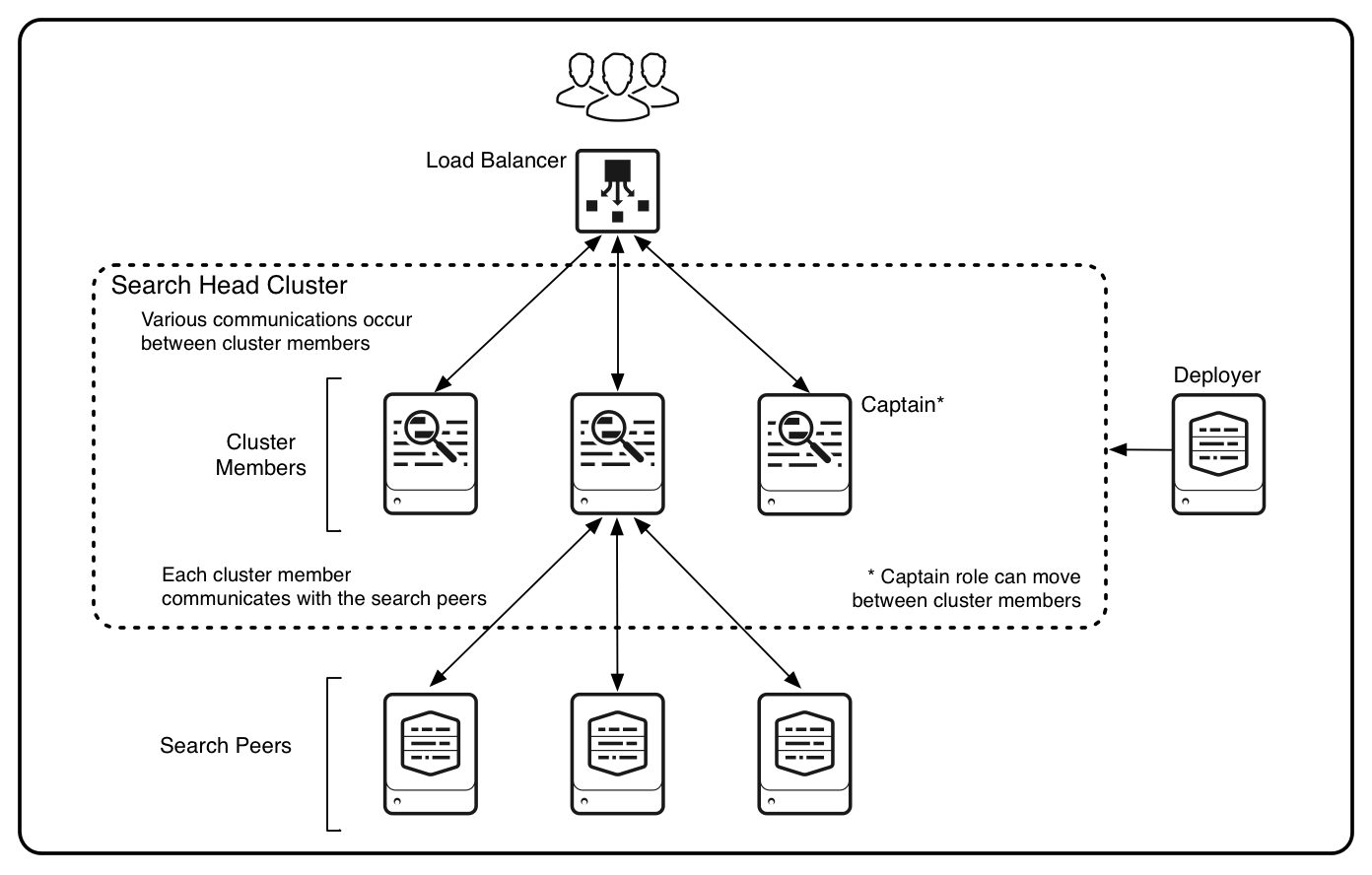
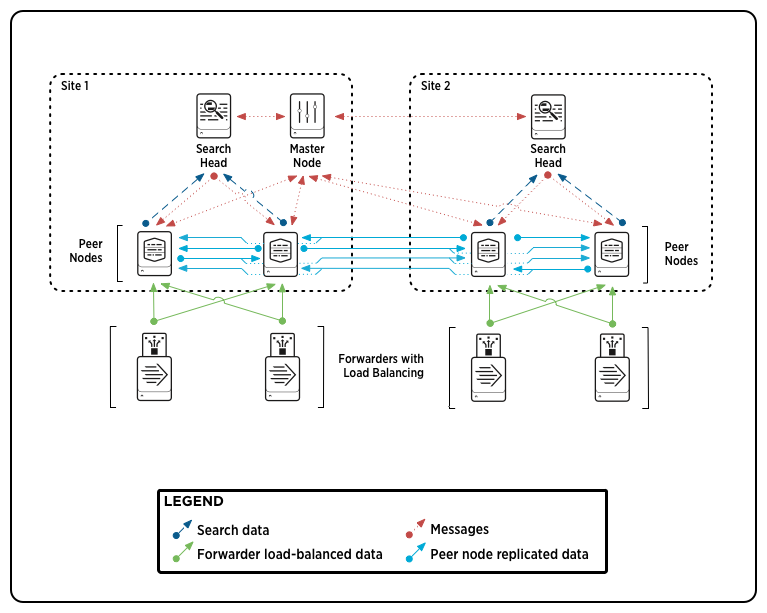
The release of Splunk Enterprise 6.2 introduced several great new features and enhancements. The new capabilities center around a new faster interface designed to assist with data onboarding, easier analytics and event pattern detection, and improved scalability and centralized management. While I would definitely recommend exploring the first two topics, this blog will focus on the latter. Core to the improvements in scalability and centralized management within Splunk Enterprise 6.2 is the introduction of Search Head Clustering. Search Head Clustering (SHC) is a direct replacement for...
Clustering: It's Not Just For Indexers
Posted by Naveed Krabbe
on Monday, December 15, 2014 - 13:34
Operational Intelligence Splunk, Search Head Clustering, Captain, Deployer, 6.2