Accelerated Data Models in a Distributed Splunk Environment
Splunk v6.0.1 is packed with new features that enhance the user experience and can provide useful, lightning fast reports. For a full overview of the new features check out this link: Splunk 6!
One of the new features that provide users the ability to build exceptionally fast reports is data models. Users can use the structure provided by the data models to create pivot tables, all without knowing Splunk’s search language. Pivot users select the data model they are interested in, then point and click their way to insightful, promotion-worthy reports. Pivot table reports can be generated at exceptional speeds due to the "High Performance Data Store". To read more about data models, pivots, and acceleration, please review the following link: About data models
A recent client of ours wanted to take advantage of all of the powerful features that come with using data models. They had a distributed environment that consisted of a single Job Server, two Search Heads, a Deployment Server, and four Indexers. The client also had a small test environment consisting of a single Search Head and an Indexer. Keeping best practices in mind, we created the data model on the test Search Head to ensure we achieved our desired results before pushing it into the production environment. Data models can be created simply through the user interface and should be assigned to a specific app. Once built, all of the configuration files that come with the completed data model are placed within the /local directory of that app.
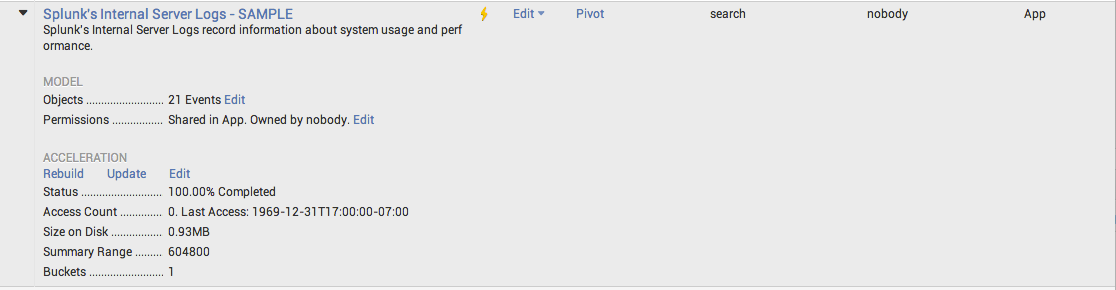
In order to take advantage of the high performance data store, we accelerated the data model. You can track the progress of the acceleration and see useful information like size and bucket count when you expand the data model manager page.
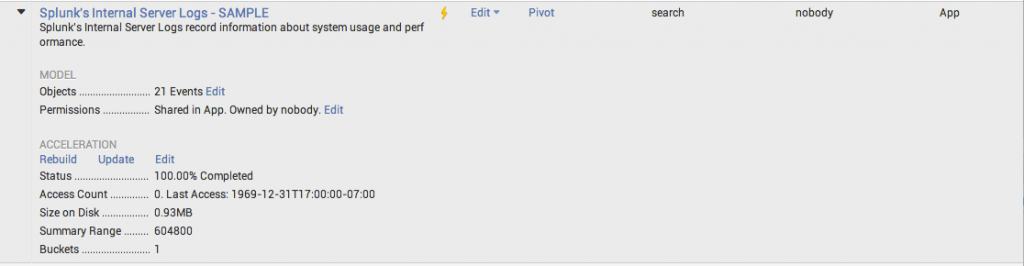
Go to the top right corner in your Splunk Web window and select Settings ---> Data Models to see this view.
After testing the data model and pivot capabilities in the test environment, we were ready to move it to production. A best practice is to use the Deployment Server to manage the distribution of configuration files/apps, so we distributed our updated app, including the data model, to all of the Search Heads and the Job Server.
By default, accelerated data model summary data is stored in: $SPLUNK_HOME/var/lib/splunk/<index_name>/datamodel_summary. We noticed that each Search Head was accelerating the data model and was in turn creating three copies in the datamodel_summary directory on the indexers. This was not a desired result for this particular client.
There are a few ways you can go about ensuring that Splunk only creates a single copy of the data model summary data. One way is to create two separate apps, one with acceleration enabled and one with it disabled. Acceleration is configurable in the datamodels.conf file using the acceleration attribute:
[my_data_model_name]
acceleration = true
Be sure to send the correct app to the correct instance of Splunk. I would suggest placing the app with acceleration enabled on the Job Server.
Another way to handle this issue is to use Search Head Pooling (SHP) and only enable the scheduler pipeline on the Job Server. The scheduler pipeline is enabled by default so you will need to be sure to update default-mode.conf to include the following:
[pipeline:scheduler]
disabled = true
With the scheduler pipeline disabled, the Splunk instance will not run any scheduled saved searches or accelerate the data model, even though it is configured to do so. However, because the data model exists on the Search Head that has the scheduler pipeline disabled, users will still be able to take advantage of the high performance data store when searching.
If you would rather not configure search head pooling and also do not want to maintain two copies of your app, you can still achieve your desired result by configuring a more complicated, slightly tricky, "off the beaten path" approach described here.
Please go out and explore all of the enhancements and benefits of the newest release of Splunk, and if you have any questions along the way, feel free to contact us at info@function1.com.
Featured Image courtesy of: http://www.zastavki.com/eng/Auto/wallpaper-42730-30.htm
- Log in to post comments
