Analyzing the word Analytics in an ever-increasing Analytical world

As you can tell from the preposterous article title, I take exception to the use, overuse, and misuse of the word Analytics. From the day the first person uttered this word, the word has taken on a life of its own. Analytics at a basic level simply means to distill data so that some information/knowledge can be gleamed in the hopes of making better informed decisions in the business arena or any other for that matter. Early Analytics came in the form of a simple spreadsheet tool such as excel and was a means to do decision , what-if or scenario analysis. Spreadsheets can be used to perform simple functions all the way up to sophisticated forecasting and modeling. Therefore, the spreadsheet can still be a very versatile analytical tool. I have seen the 'lowly' spreadsheet used extensively at a major newspaper, as a forecasting tool, and within that context the spreadsheet could be referred to as an advanced analytical tool. I have discussed Data Warehousing and Business Intelligence previously, areas which have taken spreadsheet analysis to the next level by allowing the business user to hook into multidimensional databases to slice and dice, often times directly in a spreadsheet environment like excel (i.e. using Microsoft's SQL Server Analysis Services). Yet another form of analytics can be carried out with the use of Web Analytics software. The kind of software offered by Omniture, Google Analytics (formerly Urchin), WebTrends, and others offer a glimpse into the the nature of web traffic coming to your website. These packages, when properly deployed, allow business users to look at the who, what, when and where associated to website traffic. Analytics in the web arena (on a retail site for example) could be centered around the conversion process (a goal path) usually in the form of a purchase funnel. A good commercial package would allow you to do visualizations like those seen in Fig. 1. You can see quickly that conversion is roughly a hair under 50% (304/625) from this report.
Fig 1. Conversion Funnel Report
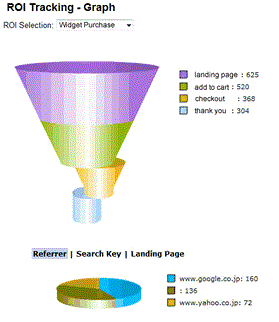
These are very useful tools and many organizations leverage them daily. However, when I think about truly advanced Analytics, I think of the work going on in area known as Data Mining and/or Knowledge Discovery and/or Machine Learning. This area of computer science is certainly pervasive today, but still not well understood by most. I knew that Data Mining had arrived while watching Steven Colbert recently. Yes the "Colbehr Repohr". He mentioned how the retailer Target can now detect, within weeks, when a woman becomes pregnant via a change in their purchase behavior. Kinda scary, but a certain reality. So what makes this possible? Understanding the the Data Mining process will certainly help, so let's explore one such process. Crsip-DM is a non-proprietary process used to the describe the steps involved in the knowledge discovery process (seen below).
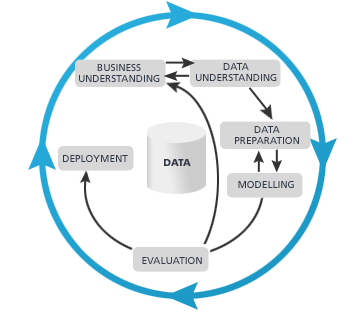
Business processes and an understanding of underlying data generated by these processes must be studied in detail. The modeler must understand the nuances of what is intended to be captured by business processes and what actually is captured. A phenomenon known as "technology adaptation" frequently occurs where end users often use a software product in ways unintended by the designer/developer. Data that may appear to be one thing may not be as it seems. I have seen this first hand where poor control in the call center can generate data in places and with meaning sometimes only understood by those capturing it! The first rule of thumb with a modeling exercise is that garbage in equals garbage out so a keen grasp of the available data is key to the success of the exercise. The second part of business understanding is determining what it is we are trying to achieve from a business perspective. Are we trying to curb subscriber churn by identifying those more like to cancel their subscription? Or Are trying to determine whether a customer will pay there bills so we can know what percentage of bad debt we can expect for forecasting purposes? These questions must be flushed out as part of the process. Data preparation is unfortunately a big part of the data mining process and those looking to put into place a sustainable modeling effort will be better off if they address ETL (Extraction Transfer Load) issues early. You have to ask yourself things like, If the model requires a new data input will the current ETL process be able to handle it? Or things like, If we currently use a column containing data with values ranging from 1-10, but the modeler wants to convert the column into a categorical data type (1-5, 6-10), can we quickly accommodate this? Good ETL platform selection is very helpful here. The Modeling phase of the exercise and evaluation go hand in hand. This is where the modeler takes a representative sample of the data at hand and actually generates a model. For example, if you were trying to predict which customers respond to your marketing offers, you would create a list of customers containing those who have responded and those who have not, including as many data points as possible. Often times a company's own internal customer data is enhanced by external data like those offered by Experian, census data, PRIZM cluster data etc. The modeler then generates a model and evaluates the model's ability to correctly predict the class of a given customer (responder vs. non-responder) . So what do you do now that you know which customers are likely to respond vs those that are not? Well potentially a bunch of different things, like reduce mail volume by reducing the number of pieces you send to those that you know are likely to respond while increasing the number of pieces (marketing efforts) that you send to those that are predicted to be non-responders. The possibilities are endless but I digress. Once the modeler is satisfied that the model accurately solves the business problem at hand, the model can be placed into a production environment. Although the process may seem complete the evaluation process is never ending to ensure that the model continues to be relevant. The nature of a model is that it can and will become stale and needs a certain level of vigilance, hence the circular nature of the Crisp-DM process. Now you can see why the Data Preparation stage is very important. The model will need changing at some point, and an agile ETL environment will be key to success if your organization is to successfully reap the benefits of Data Mining without interruption. With this introduction to a data mining process, you can hopefully see how organizations can gather information to "predict the future". In my next article I will focus on the modeling itself; specifically an area of Data Mining called Classification which is synonymous with Predictive Analytics. Until next time! -Mitul
- Log in to post comments
