Off the beaten path - Splunk search head pooling without search head pooling?? Its possible...

Recently I was working with a client that was Splunk savvy and they wanted to try to implement something that was, what I would consider, off the beaten path.
Here is the challenge:
This client was looking for a way to be able to take advantage of having multiple search heads for high resource availability and resiliency, without taking a hit on performance. One approach to go about providing high availability and resiliency of search heads is to use a Splunk feature called search head pooling. The one downside of using search head pooling is, due to all of the Splunk knowledge objects being shared by the search heads and indexers are stored on shared storage (NFS or CIFS), search performance is dependent on the read/write speed of the shared storage. These speeds are usually not up to par with the search performance expectations of Splunk. We needed a solution that would provide the search head performance and resiliency the client was looking for. Clients usually deal with the slow speeds of search head pooling or decided to scrap the idea entirely and have dedicated search heads. This client however, wanted the best of both worlds, high performance and resiliency!
Environment:
The production Splunk environment at this particular client consisted of 4 physical indexers (IDX), 2 physical search heads (SH) sitting behind a load balancer, and a virtual job server (JS). All instances of Splunk were version 5.0.3.
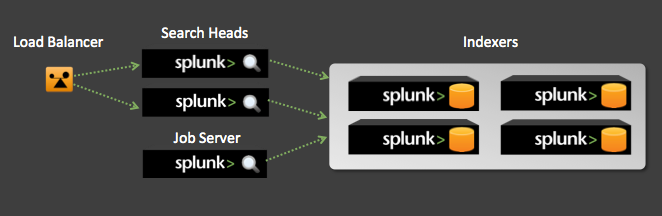
Strategy:
In order to provide the client with SH performance and resiliency we will need to rsync certain directories to and from the JS and 2 SHs.
Secure the Environment
To ensure the strategy will be successful we need to ensure the Splunk user environment is "locked down". This means we must ensure that all users (non-admin users) can not save any knowledge objects in the app context. Meaning we have to be sure that users can only write to their own user directory $SPLUNK_HOME/etc/users/<user_name> and NOT to the$SPLUNK_HOME/etc/apps directory. We can accomplish this by creating a local.meta file in the /metadata directory of every app on the SHs that includes the following, and only the following:
[] access = read : [ admin, <specific_role> ], write : [ admin ] export = system
If you are using a deployment server to manage your configuration files, you would place this local.meta file in the metadata directory in every deployment-app that was would be sent to your JS or SHs. This configuration will only allow those with admin rights to write to the $SPLUNK_HOME/etc/apps directory. Replace <specific_role> with the group specific to this app. (i.e. sysadmin_user, infosec_user)
ADVANCED: You can create a group_user and a group_admin role for each department at your company. This will allow the Splunk Admin to have an admin POC on each team that can administer their own group. (i.e. infosec_user and infosec_admin) For more information about configuring/creating roles in Splunk look here.
Also, you must ensure that the SHs can not run scheduled searches. The JS should be the the only instance of Splunk that runs scheduled searches. To configure this, create a default-mode.conf file in the /local directory of your search head base app on your deployment server (be sure that the JS does NOT receive this configuration). Only add the following to default-mode.conf:
[pipeline:scheduler] disabled = true
With this configuration, the search heads will not be able to run scheduled searches. This will ensure that all of the resources dedicated to the SHs will be used for users' searches, not scheduled searches.
Using this strategy will require the Splunk Administrator to play a more active role in administering the entire environment. Users will have to submit all requests for creation/removal of knowledge objects, such as scheduled searches, tags, eventtypes, etc, to the Splunk Administrator for approval and creation/removal.
Use rsync
You must be familiar with rsync in order to utilize this strategy.
To achieve the goal of giving users the ability to log into one of the SHs through the load balancer and not notice any difference between the two, we must rsync a few of the directories on the JS and SHs. In particular we will need to rsync the following from the JS to both SHs:
- $SPLUNK_HOME/var/run/splunk/dispatch/rt_scheduler*
- $SPLUNK_HOME/var/run/splunk/dispatch/scheduler*
- $SPLUNK_HOME/var/run/splunk/dispatch/subsearch_scheduler*
- $SPLUNK_HOME/etc/apps
Rsync'ing these directories will allow the SHs access to the data created by the scheduled saved searches that ran on the JS. Be sure to use the rsync --delete flag for the .../dispatch/ directories listed above. This will ensure that the JS's version will override the local SH version. The result sets of the scheduled searches are commonly and frequently used to update lookup tables, display results on dashboards, and many others, so it is extremely important that these directories are replicated frequently on all of the SHs.
NOTE: If you have SSL enabled and you have a app on your JS that contains an outputs.conf with the SSL password, be sure to use the rsync --exclude flag to exclude that outputs.conf. ie. --exclude "apps/function1_all_forwarders_outputs/local/outputs.conf". This will cause authentication issues if this outputs.conf file is shared with the SHs.
We will also need to rsync the following directory to and from the SHs:
- $SPLUNK_HOME/etc/users
This will ensure that if any user specific knowledge objects are created/updated, those changes will be available on the other search head. Use the --update rsync flag here and not the --delete flag so if changes occur on SH1 and its time for SH2 to rsync its $SPLUNK_HOME/etc/users to SH1, the changes on SH1 will not be overridden.
We decided to run the JS to SHs rsync script every 3 mins to ensure a low lag time when updates show up on each SH. The SH to SH rsync script will also run every 3 mins, however, each will run on every other 3rd min. For example, SH1 will run on the 0,6,12,18,… minutes and SH2 will run on the 3,9,15,21,… minutes. If you are ok with a larger lag time, maybe run the scripts every 5 to 10 mins.
Refresh splunkd
After the rsync runs and configuration files have been updated, you must let splunkd know that changes have occurred. One way to do this, without restarting splunkd and kicking off all users logged into Splunk, you can run a debug/refresh?entitiy=<entity_name>. Look to this splunkbase.com answer for an example. The list of entities you should refresh are as follows:
admin/eventtypes admin/fvtags admin/fields admin/lookup-table-files admin/macros admin/nav admin/passwords admin/savedsearch admin/transforms-extract admin/transforms-lookup admin/views admin/viewstates admin/workflow-actions data/ui/nav data/ui/views
You may not need to refresh all of the entities listed above. Be sure to include all that could be affected in your environment. For a complete list of the entities available, go to:
http[s]://<splunkweb_hostname>:<splunkweb_port>/debug/refresh
Replace <splunkweb_hostname> with the name of your Splunk instance and <splunkweb_port> with the port you assigned.
NOTE: In order to run a debug/refresh, you must be logged into the Splunk instance and have admin rights. Build this into your rsync script so you can run the debug/refresh command immediately after the rsync commands run. This requires you to log into the Splunk instance and save the session info in a cookie within the script. One way to accomplish this is by using the wget command with the following flags: --save-cookies, --post-data, and --load-cookies.
Outcome
So far this strategy has worked well for the client, but tread carefully as this approach can become very complicated and produce undesired results. There are a variety of things to watch out for, but for one, the JS and SH must have identically named apps and knowledge objects. You can ensure this by using a deployment server to distribute them. Another point to keep in mind is the version of Splunk on the JS and SHs. They were exactly the same in this case (v 5.0.3), so be sure to carefully test this strategy if your Splunk instances are running different versions.
If this is something you would like to tackle, please do not hesitate to reach out to us at info@function1.com. We would be more than happy to make the journey off the beaten path with you.
Happy Splunking!!
image courtesy of: http://farm6.staticflickr.com/5030/5767398052_1c10f2bd61_z.jpg
- Log in to post comments

{kind=link}