Splunking The Billboard Hot 100 with help from the Spotify API
There's a lot of data out there and once we put it into Splunk, there's a lot of interesting information we can pull out of it, so why not have a trip down memory lane and see what sort of songs pop up when going through the Billboard Hot 100 charts from now back to 2000?
First, I found a scraper for the data - thank you Allen Guo for your Billboard charts scraper - and output the data in this format:
date | title | artist | weeks | delta | current | peak | previous | spotifyID
I did so with this python script:
import billboard
import json
import datetime
outfilename = 'output.psv'
counter = 1000
chart_type = 'hot-100'
chart = billboard.ChartData(chart_type)
chart_date = '2017-07-01'
first_line = 'date | title | artist | weeks | delta | current | peak | previous | spotifyID\n'
with open(outfilename, 'a') as outputfile:
outputfile.write(first_line)
for i in range (1,counter+1):
for position in range (0,99):
song = chart[position]
line_out = unicode(str(chart_date) + ' | ' + unicode(song.title) + ' | ' + unicode(song.artist) + ' | ' + str(song.weeks) + ' | ' + str(song.change) + ' | ' + str(position) + ' | ' + str(song.peakPos) + ' | ' + str(song.lastPos) + ' | ' + str(song.spotifyID) + '\n')
songidout = str(song.spotifyID) + '\n'
with open(outfilename, 'a') as outputfile:
outputfile.write(line_out.encode('utf8'))
print chart.previousDate
print chart[0]
chart_date = chart.previousDate
chart = billboard.ChartData(chart_type, str(chart.previousDate))
print 'done'Next, I created a props.conf with these settings:
[billboard_top_100] CHARSET=UTF-8 MAX_DAYS_AGO=10000 MAX_DAYS_HENCE=25 NO_BINARY_CHECK=true SHOULD_LINEMERGE=false TIME_FORMAT=%Y-%m-%d category=Custom description=Billboard Top 100 disabled=false pulldown_type=true REPORT-BillboardMainFields=REPORT-BillboardMainFields EVAL-Position = CurrentPosition+1
Since all of my data is on different lines (I output it that way) we set SHOULD_LINEMERGE to false. Other things we need to set include MAX_DAYS_HENCE because Billboard charts can, weirdly, be up to nearly 3 weeks in the future, and MAX_DAYS_AGO because the default of 2000 days just isn't enough to take us back to party like it's 1999.
(The EVAL statement is in there because, if you notice my python code above, position goes from 0-99, and I made the rookie mistake of outputting position instead of position+1, so I used an eval statement to fix it. If you debug your code and don't run it at 2AM just trying to get the thing running, you probably won't need that sort of statement in there. I also didn't want to reindex data, even though it was only about 12 MB of data.) Public Service Announcement: Always debug your code because computers do what you tell them to do, not what you want them to do...
And a transforms.conf here:
[REPORT-BillboardMainFields] DELIMS = "|" FIELDS = "Chart_Date","Title","Artist","WeeksOnChart","ChangeFromPrevious","CurrentPosition","PeakPosition","PreviousPosition","spotifyID"
While I could have used "INDEXED-EXTRACTIONS" with the PSV command, I stuck with keeping the big 5 as my only indexed fields, and did these extractions here.
There are plenty of things that we can do with this data, like answer the following random questions that probably tell you more about the workings of my mind than about music trends:
- Who had more Billboard top 100 hits, Miley Cyrus or Hannah Montana? (Surprisingly, each had exactly 18 charted songs.)
- How many pop songs from my nascent adolescence had I completely forgotten about until setting out on this task? (Too many to count.)
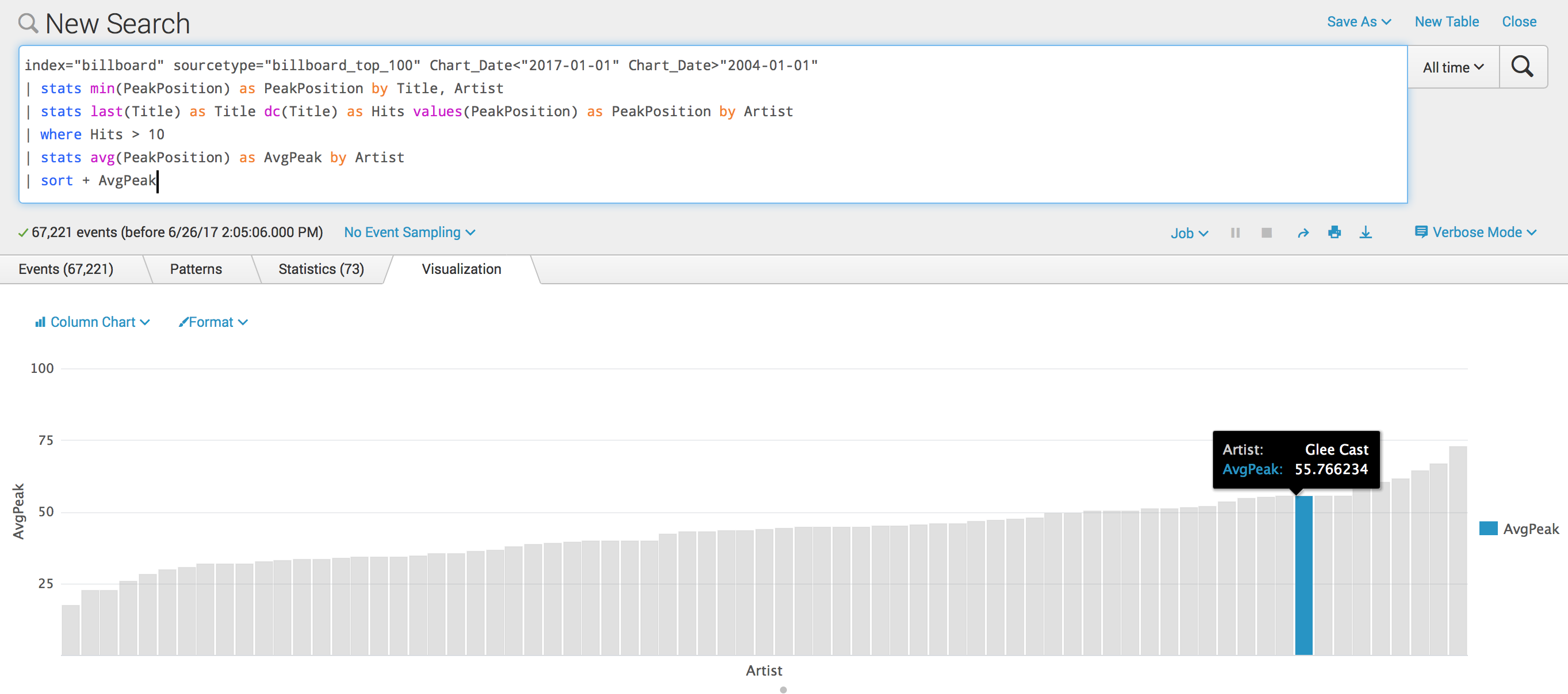
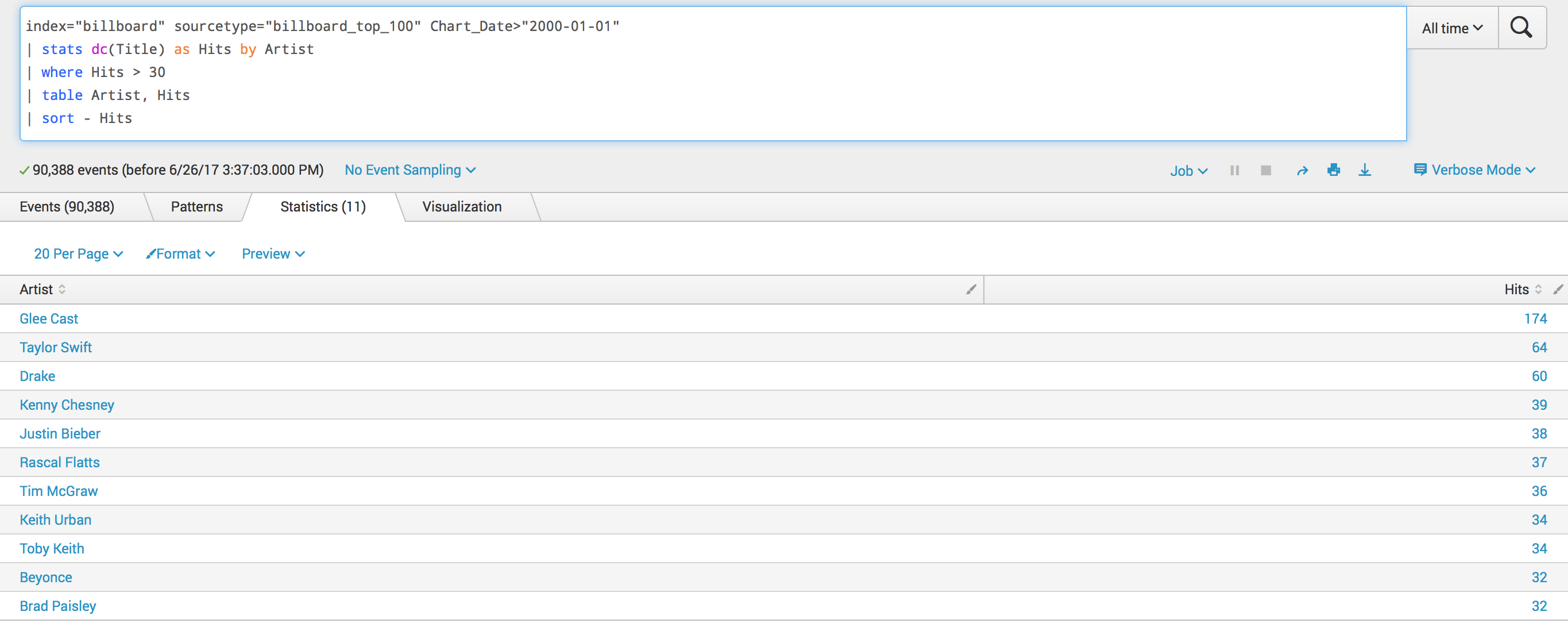
- What artist/group/band has had the most top 100 hits since 2000? (More on this later at this post, because: reasons.)
- What's the stats on Beyoncé's songs compared to Destiny's Child? (Destiny's Child charted 18 songs, but Queen Bey has charted 48.)
- What happened to the solo careers of the Black Eyed Peas? (will.i.am charted 18 hits; 8 of which he was the main or solo artist, 10 of which he was just featured. Fergie charted 12; 9 of which she was the main or solo artist, 3 of which she was featured.)
- Were there REALLY that many songs by the Black Eyed Peas? (Damn, the answer is yes. Yes, there were 16 charted Black Eyed Peas songs, including one that featured Macy Gray.)
- What ever happened to Macy Gray? (Hmmm, seems like there are some questions even Splunk can't answer.)
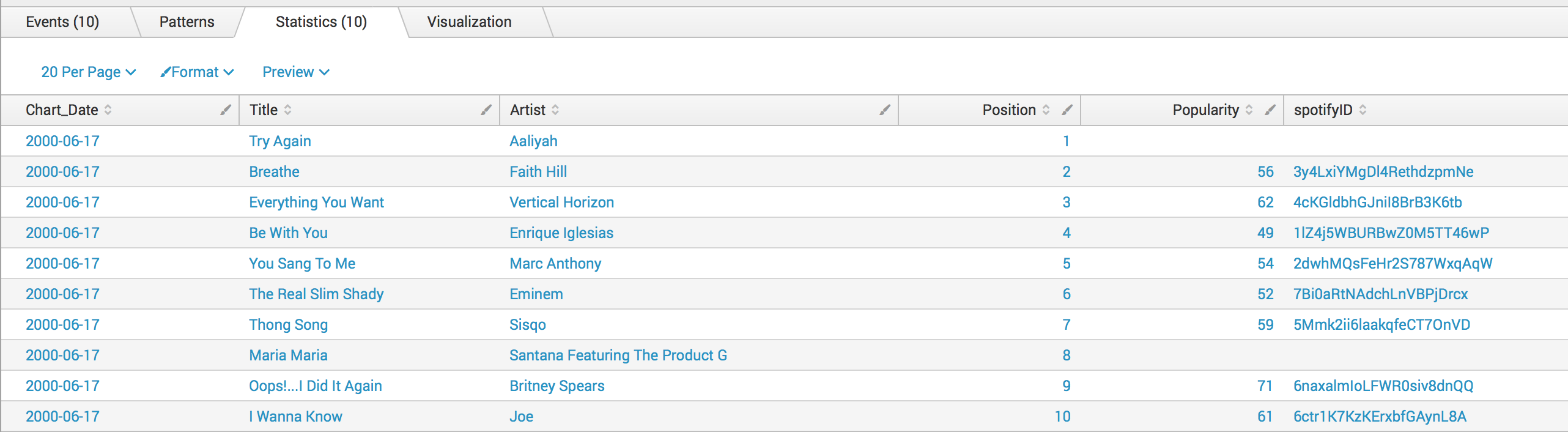
And, while we can do a lot with this data, we can do some more if we take these songs and link them to Spotify data, so let's do that by first isolating song IDs in a file:
index="billboard" Chart_Date>2000-01-01 | stats values(spotifyID) as IDs | dedup IDs | mvexpand IDs | fields - _mkv_child | outputlookup song_ids.csv
import codecs, requests, json, os, time, spotipy, spotipy.util, sys
inputfile = 'June26_songidonly.csv'
outfilename = 'June26_spotify_info.json'
token = 'my secret token that spotify generated for me'
headers = {'Accept': 'application/json',
'Authorization': 'Bearer ' + token}
with codecs.open(inputfile, 'r', 'utf-8') as f:
for song_id in f:
currentsong = requests.get('https://api.spotify.com/v1/tracks/?ids=' + song_id.strip(), headers=headers)
print(currentsong)
with open(outfilename, 'a') as outputfile:
json.dump(currentsong.json(), outputfile)
print 'done'
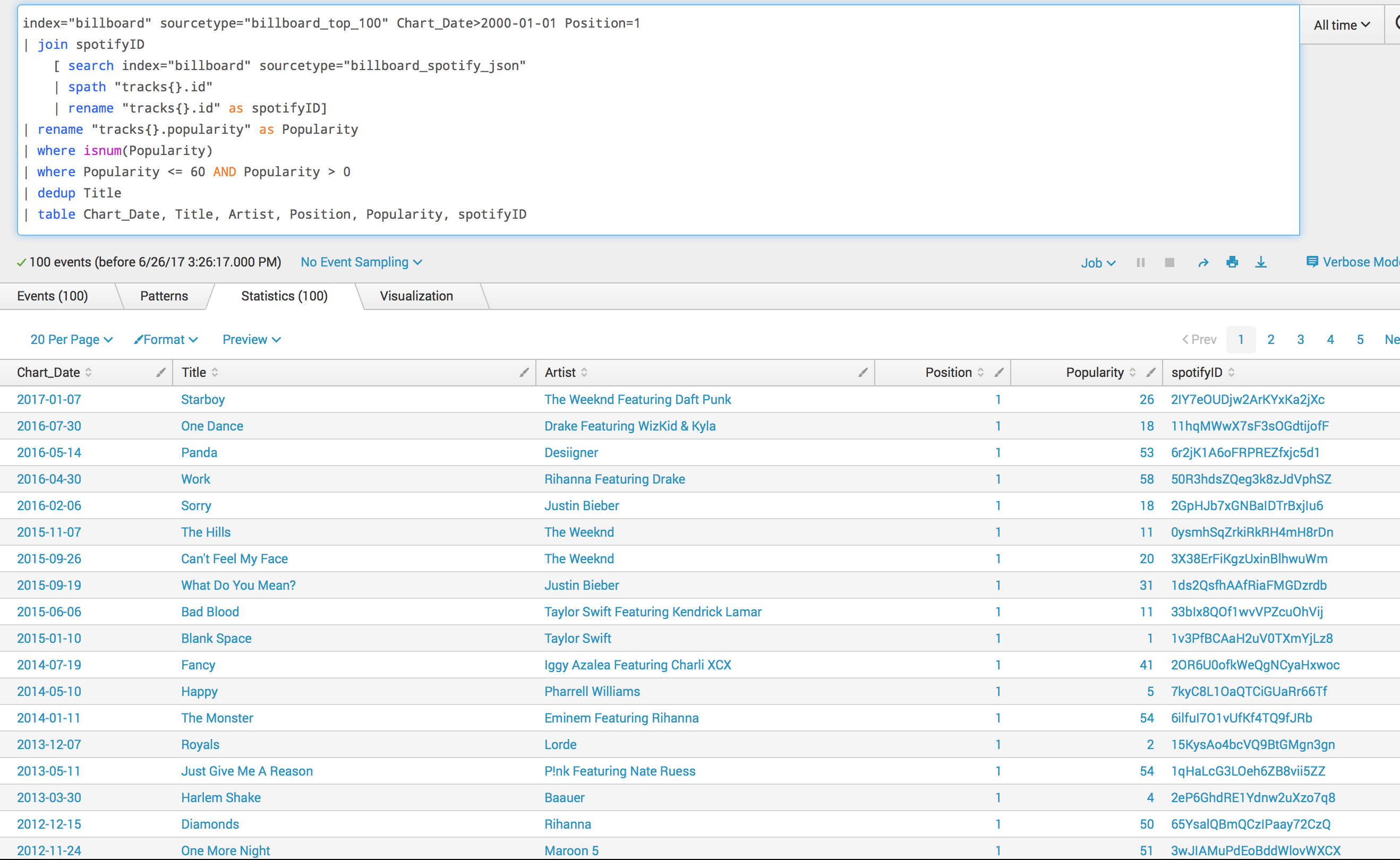
index="billboard" sourcetype="billboard_top_100" Chart_Date > 2000-01-01
| join spotifyID
[ search index="billboard" sourcetype="billboard_spotify_json"
| spath "tracks{}.id"
| rename "tracks{}.id" as spotifyID]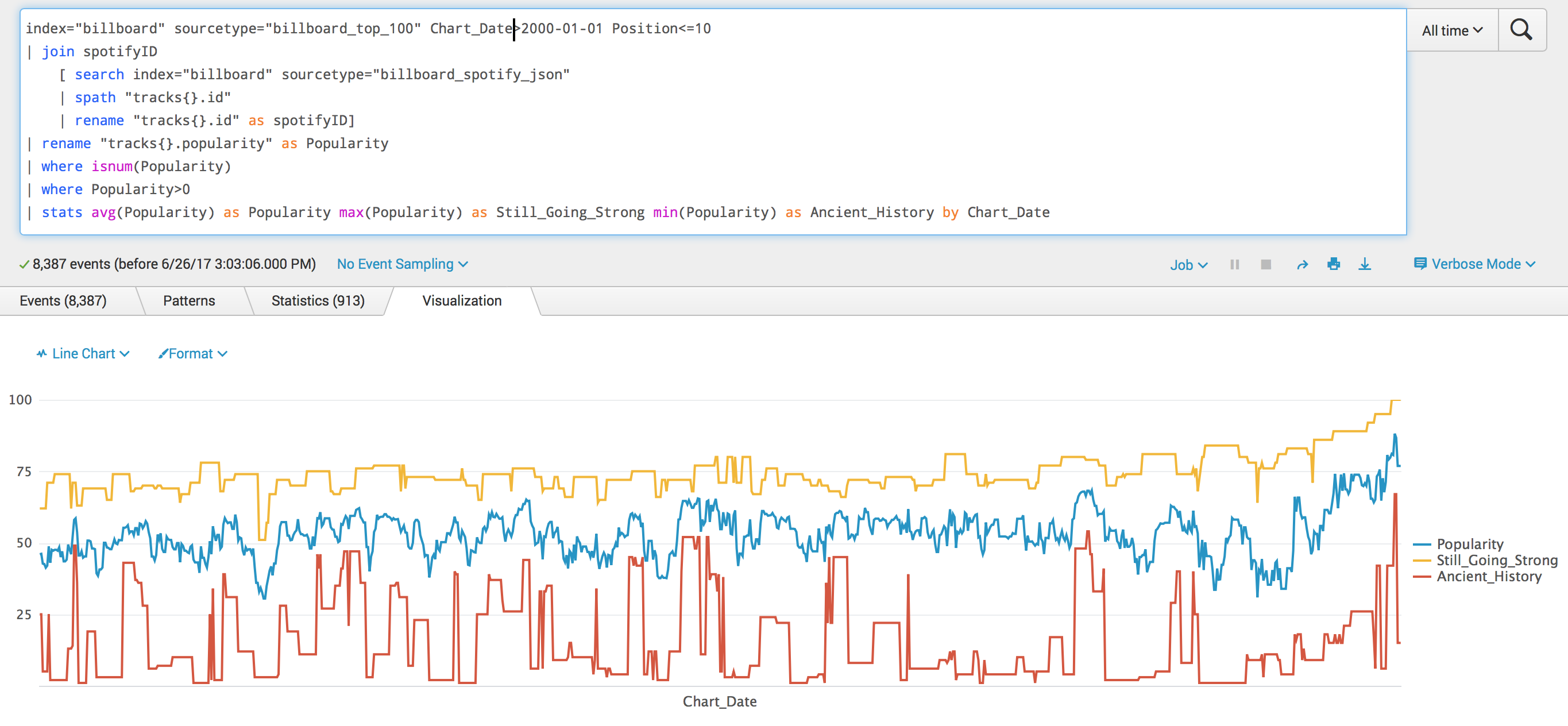
- Log in to post comments
