Using Datasets in Splunk
By: Karthik April 12, 2017



Greetings, fellow Splunkers! I'd like to discuss a feature released in Splunk 6.5 called datasets. This feature combines the usefulness of lookups, to enrich data, with data models to provide robust data analysis either through the use of SPL or through the UI.
In Splunk 6.5, "datasets" are a term encompassing data models, lookup files, and lookup definitions. These datasets have also added the new capability of a table dataset.
We're going to walk through a use case with datasets where we are going to create a large dataset. Next, we will create two child datasets: one for our Sales team and one for our Web team. The sample data I will be using is the Splunk tutorial data.
After getting that data, install the datasets add-on, available at Splunkbase for Splunk Enterprise users. If you are using Splunk Cloud, the add-on is already installed.
Note: the data below uses two lookups to add http status messages and to correlate the tutorial productID with a price. (You can get the files here: http_status.csv and prices.csv)
Then, after going to the Search App, you can create datasets using the "Datasets" option, which replaced the old Pivot option.
Pre Splunk 6.5:

Splunk 6.5:

Next, you can quickly create datasets with different sources, events, and field types. Click on indexes and source types.

Pick at least one index and, if you'd like, a sourcetype. You can pick the fields that you'd like to import into your dataset. After doing that, you can summarize your fields, as well as update in SPL what you'd like to pick.

After using the UI to select the index, sourcetypes, and fields above, the search string below was generated in SPL: (it is highlighted above in blue as well)
((index="tutorial_data") (sourcetype="access_combined_wcookie" OR sourcetype="secure" OR sourcetype="vendor_sales")) | fields "_time", "action", "bytes", "categoryId", "clientip", "Code", "index", "price", "product_name", "productId", "referer_domain", "sale_price", "source", "sourcetype", "status", "status_description", "status_type"
Splunk UI created this query when I selected 1 index, 3 sourcetypes, and 17 fields. You can use either SPL or the UI to update the search. If you knew before starting that the above was the search you wanted, you could actually have clicked on "Search (Advanced)" and entered the SPL command above to generate your dataset.
When comfortable up to this step, hit "Save As" and then choose a name. By default, datasets permissions are set to private, so make sure to set the permissions appropriately. For now, I'm setting everyone to read and admin to write. One could also limit certain super users to read/write, and only allow read rights to the roleswho have a need to know or access all the data in the dataset.

Now that we have a table dataset, we can decide what to do with it. Let's create child datasets from this: one with the sales numbers for the sales team, the other with web errors for the Web team to look at.
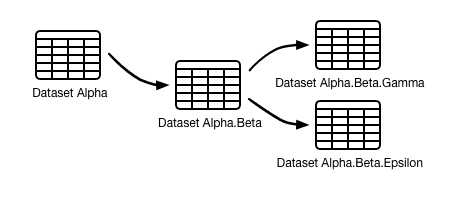
You can create datasets that branch from other datasets. This means that child dataset permissions can be set to adhere to the least-privilege principle for data security and access, while providing other users with elevated privileges to access the parent dataset.
The process of dataset extension or creating child datasets from a parent dataset is shown in the datasets doc on Splunk Docs:
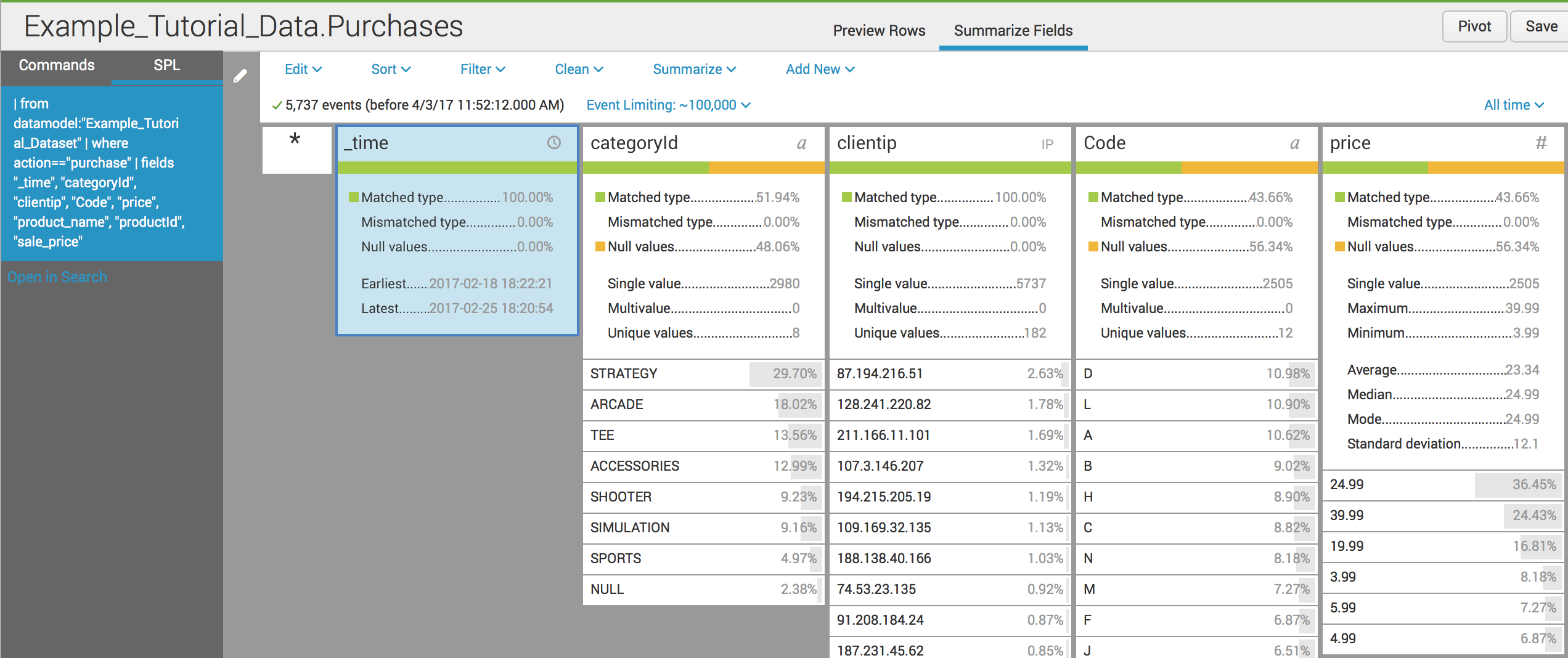
First, we are going create a child dataset that will be called "Example_Tutorial_Data.Purchases." Go to "Datasets" and click on "Existing Dataset." It will prompt you for a dataset to use, and we will use "Example_Tutorial_Data."

And here you can see that the SPL started with the | from command, and then the | where action=="purchase" was added. You can also see that fewer fields were sent to this dataset. For example, does the sales team need to know the web status, or do they care more about purchases, prices, and products? We also have to make sure to set permissions so only the Sales users can access this dataset.
Once we have that, we can create a pivot for sales numbers by clicking on the pivot button, and we can get Purchases by Product Name and Price, saved as a report that the Sales team can use whenever they'd like:

Then, we can create a different dataset extending from our original dataset for the web team to look at.

Just as with the Sales team, we have sent fewer fields into the dataset, now called "Example_Tutorial_Data.Web_Errors" by taking the original dataset and restricting it to | where status >=400. We also have to make sure to set permissions so only the Web Team users can access this dataset.
From here, we can create a report for the Web team to look at, from the pivot menu for Web Errors based on the user's action:

This new tool is timesaving and makes the UI experience more powerful. The table datasets, like the data model datasets, can be accelerated in order to query large amounts of data quickly. One can extend data tables in order to make it so that different groups have the information they need to use Splunk effectively, while protecting data security and avoiding unauthorized access.
Datasets are very versatile and the use case above is just one of the many ways the updated datasets tool can be used and extended past previous data model applications.
If your team is looking for support with leveraging Splunk for data solutions, we can help - send us an email at info@function1.com or visit our Contact page.
- Log in to post comments
Categories
Best Practices (97)
Cool Tools (42)
Data Security (12)
Development (66)
Drupal (44)
Enterprise 2.0 (19)
Function1 (52)
Operational Intelligence (113)
Uncategorized (4)
Web Experience Management (110)
Cool Tools (42)
Data Security (12)
Development (66)
Drupal (44)
Enterprise 2.0 (19)
Function1 (52)
Operational Intelligence (113)
Uncategorized (4)
Web Experience Management (110)
